Every capability, highlighted.
Every feature below is in src/. Grep from any claim to a file.
Local-first
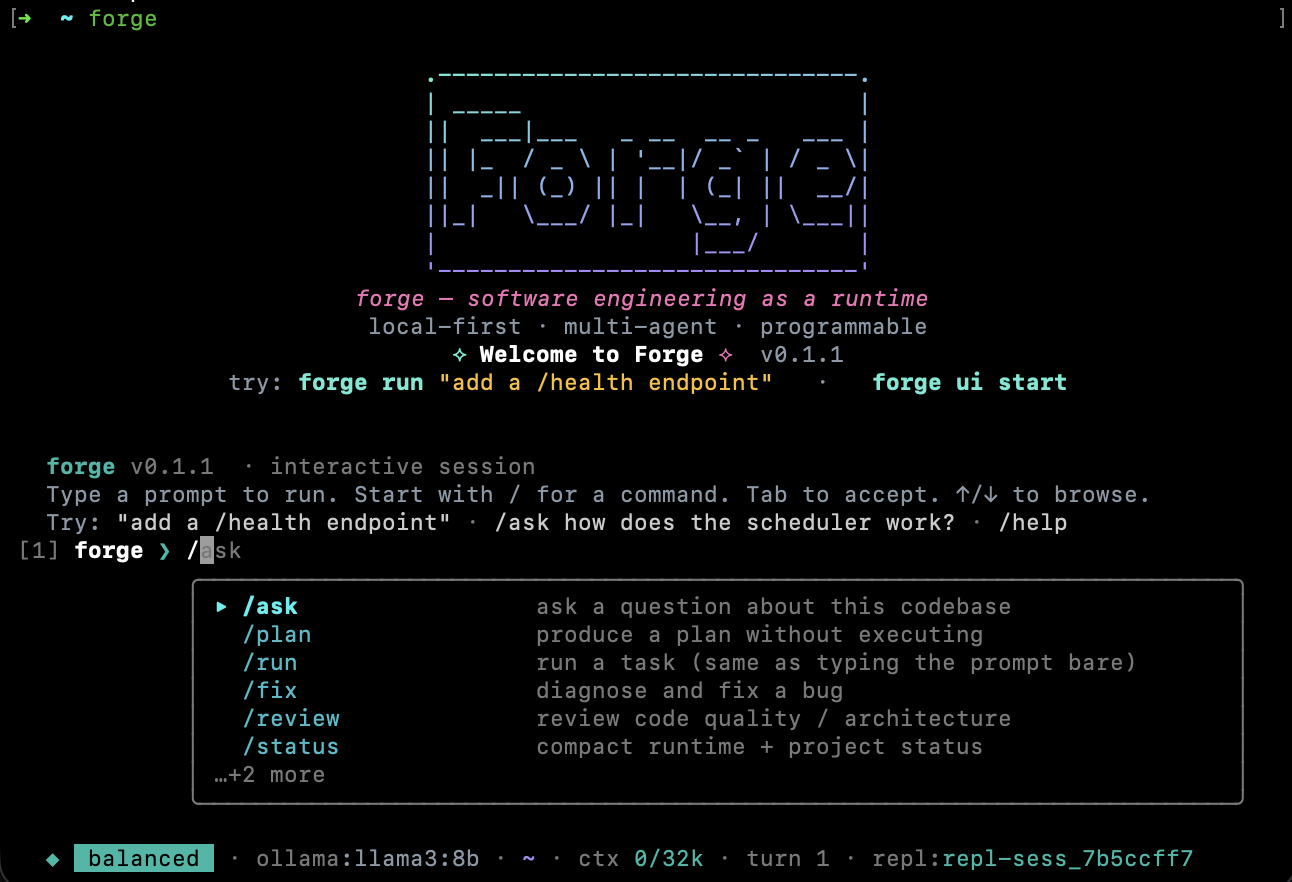
Auto-detects Ollama, LM Studio, vLLM, llama.cpp. Hosted Anthropic / OpenAI / Azure / Groq / LocalAI / Together / Fireworks are opt-in.
Iterative executor
Model sees every tool result (stdout / stderr / exit) and adapts within a step. Mode-capped turn budgets.
Validation gate
Post-step typecheck / lint failures re-enter the loop as tool results — fixed before the next step runs.
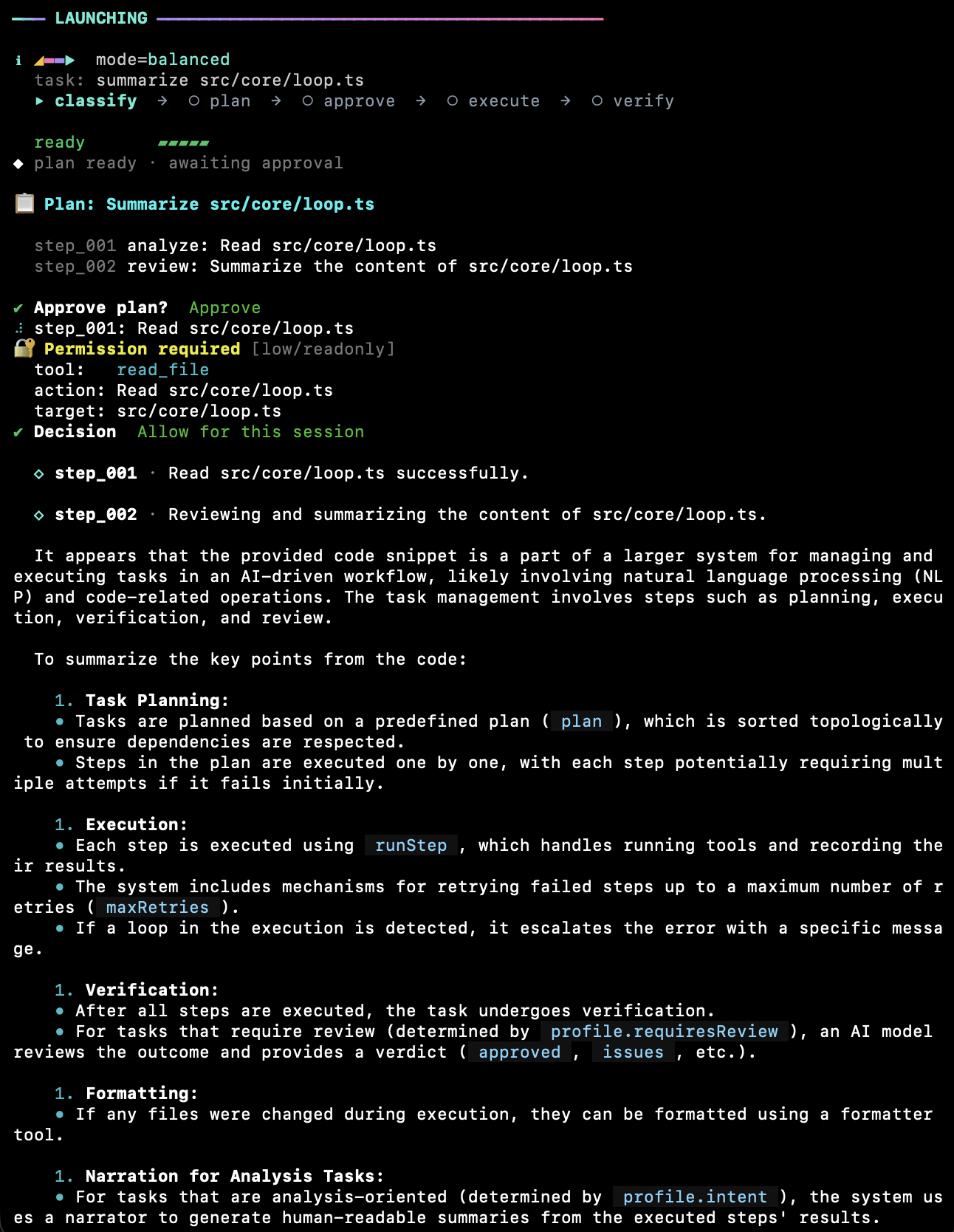
DAG planner
Plans have step dependencies, risk annotations, explicit tool calls. Auto-fixer repairs common issues; cycles rejected.
Reviewer + debugger
Reviewer gates completion. On terminal failure, debugger agent diagnoses root cause before marking failed.
4-tier memory
Hot (session) · warm (SQLite recent) · cold (lazy project index) · learning (patterns with decaying confidence).
Default-deny permissions
Risk × side-effect × sensitivity classified at every call. --skip-permissions only waives routine prompts.
Realpath sandbox
Every path resolved to realpath, confined to project root. Always-forbidden targets (SSH keys, AWS creds) hard-blocked.
Shell risk classifier
Commands rated before execution. rm -rf /, sudo, fork bombs, curl-to-shell hard-blocked.
OS keychain
macOS Security, libsecret, Windows DPAPI. AES-GCM encrypted fallback if unavailable.
Concurrent-writer safe
REPL + UI + subagents edit the same conversation via POSIX O_APPEND + mkdir lockfile fallback.
Prompt-injection defence
Untrusted content (web / MCP) fenced as data, never instructions. Redactor scrubs secrets before logs.
MCP bridge
Model Context Protocol: stdio + HTTP-stream. OAuth 2.0 + PKCE or API-key auth. Tokens in keychain.
Skills & instructions
Markdown + YAML frontmatter in ~/.forge/skills/. Per-project overrides.
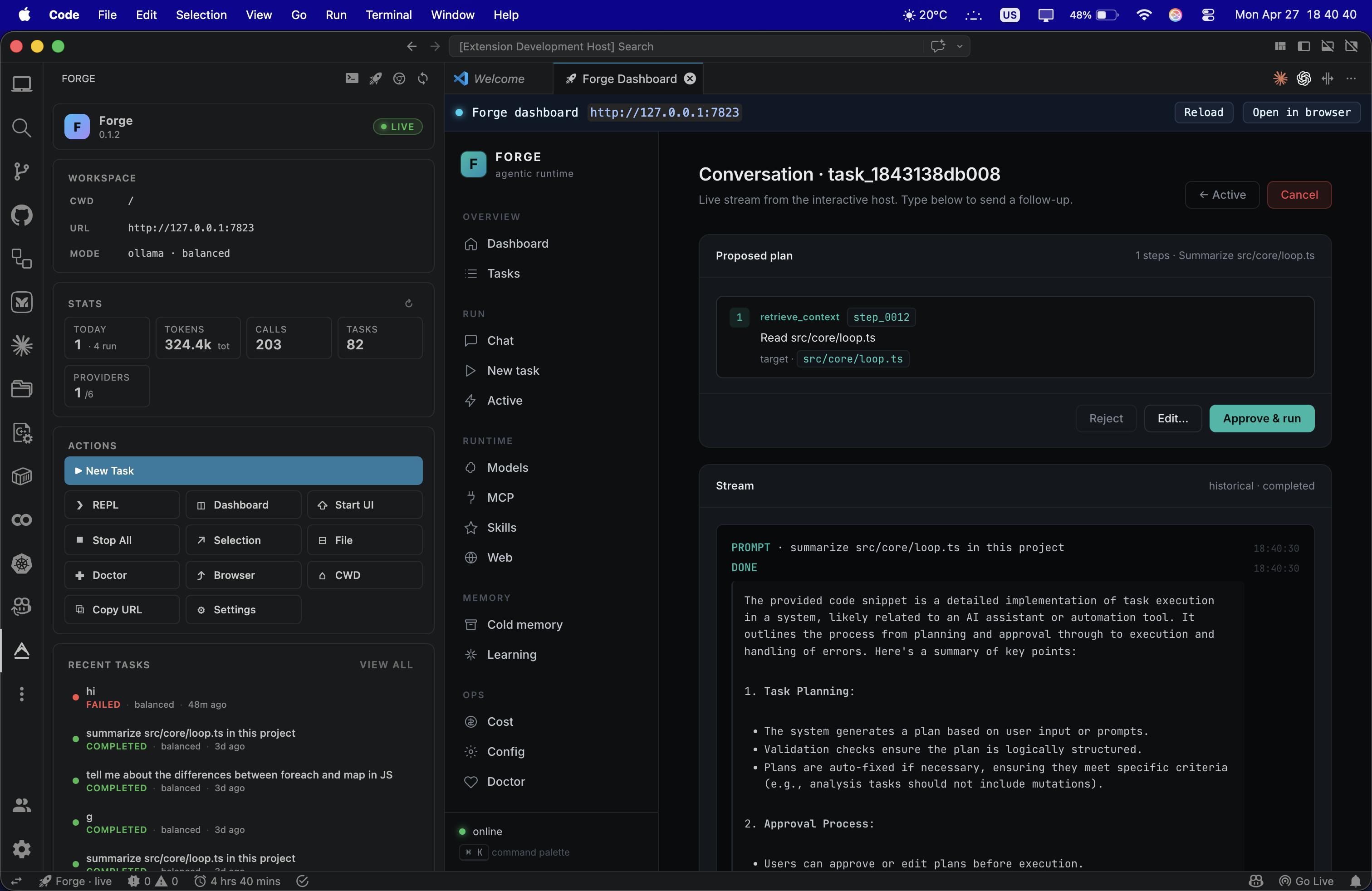
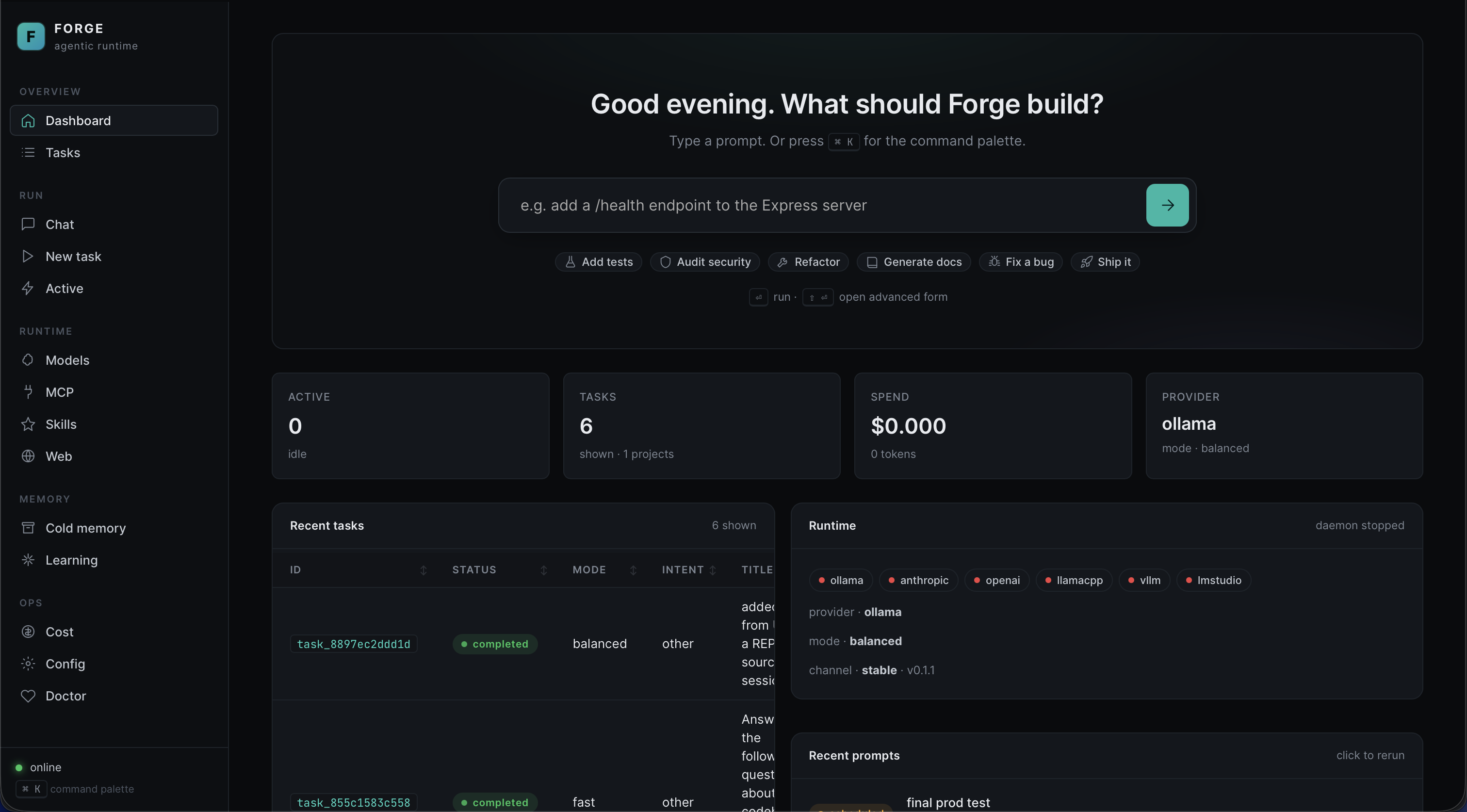
Live dashboard
HTTP + WebSocket UI. Vanilla JS, < 100 KB, zero CDN. Delta watchers ref-counted across tabs.
Router reliability
Per-provider rate limit, circuit breaker, prompt cache, USD cost ledger. 1.5 s provider probes.
Release signing
Manifest signed with Ed25519. SHA-256 per artefact. npm publishes with provenance.
Multi-arch containers
Single Dockerfile serves CLI + UI. Non-root, HEALTHCHECK, OCI labels, ~355 MB.